formazione-python
Machine Learning in Python
Il Machine Learning è una branca dell’Intelligenza Artificiale che si occupa di creare algoritmi in grado di apprendere dai dati. In questo approfondimento vedremo come utilizzare Python per creare modelli di Machine Learning.
Creazione di un modello
Ecco un esempio di creazione di un modello di Machine Learning:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Carica il dataset
df = pd.read_csv("dataset.csv")
# Dividi il dataset in training e test set
X = df.drop("target", axis=1)
y = df["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Crea il modello
model = LinearRegression()
model.fit(X_train, y_train)
# Valuta il modello
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
In questo esempio, viene creato un modello di regressione lineare per predire un target a partire da un dataset.
Utilizzo del modello
Ecco un esempio di utilizzo del modello:
# Utilizza il modello per fare predizioni
predizione = model.predict([[1, 2, 3, 4]])
print(predizione)
In questo esempio, viene utilizzato il modello per fare una predizione a partire da nuovi dati.
Esempi di modelli
Ecco alcuni esempi di modelli di Machine Learning che possono essere creati con Python:
- Regressione Lineare
- Regressione Logistica
- Support Vector Machine
- Random Forest
- K-Nearest Neighbors
- Naive Bayes
- Neural Network
Esempi di dataset
Ecco alcuni esempi di dataset che possono essere utilizzati per creare modelli di Machine Learning:
- Iris
- Wine
- Breast Cancer
- Boston Housing
- MNIST
- CIFAR-10
- IMDB
Esempi di librerie
Ecco alcune librerie di Python che possono essere utilizzate per creare modelli di Machine Learning:
- scikit-learn
- pandas
- numpy
- matplotlib
- tensorflow
- keras
- pytorch
- xgboost
- lightgbm
- catboost
Esempi di applicazioni
Ecco alcuni esempi di applicazioni di Machine Learning che possono essere create con Python:
- Predizione di prezzi
- Classificazione di immagini
- Riconoscimento di testo
- Traduzione automatica
- Chatbot
- Raccomandazioni
- Analisi del sentiment
Esempi di strumenti
Ecco alcuni esempi di strumenti che possono essere utilizzati per creare modelli di Machine Learning con Python:
- Jupyter Notebook
- Google Colab
- Kaggle
- Streamlit
- Flask
- FastAPI
- OpenAI
Esempio 1
Ecco un esempio di creazione di un modello di Machine Learning con Python:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
def predict_salary(years_of_experience):
raw_data = {"years_worked": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], "salary": [
45, 50, 60, 80, 110, 150, 200, 300, 400, 500]}
df = pd.DataFrame(raw_data)
X = np.array(df["years_worked"]).reshape(-1, 1)
y = np.array(df["salary"]).reshape(-1, 1)
train_X, test_X, train_y, test_y = train_test_split(
X, y, random_state=0, test_size=0.20)
model = LinearRegression()
model.fit(train_X, train_y)
y_prediction = model.predict([[years_of_experience]])
print("Prediction: ", y_prediction)
y_test_prediction = model.predict(test_X)
y_line = model.predict(X)
print("Slope", model.coef_)
print("Intercept", model.intercept_)
print("MAE", mean_absolute_error(test_y, y_test_prediction))
print("r2", r2_score(test_y, y_test_prediction))
plt.scatter(X, y, s=12, color="blue")
plt.xlabel("Years (Exp)")
plt.ylabel("Salary")
plt.plot(X, y_line, color="red")
plt.show()
years_of_experience = 13
print("Years of experience:", years_of_experience)
predict_salary(years_of_experience)
# Output:
# Years of experience: 13
# Prediction: [[537.72015656]]
# Slope [[46.99608611]]
# Intercept [-73.22896282]
# MAE 29.01174168297456
# r2 0.9552474870490842
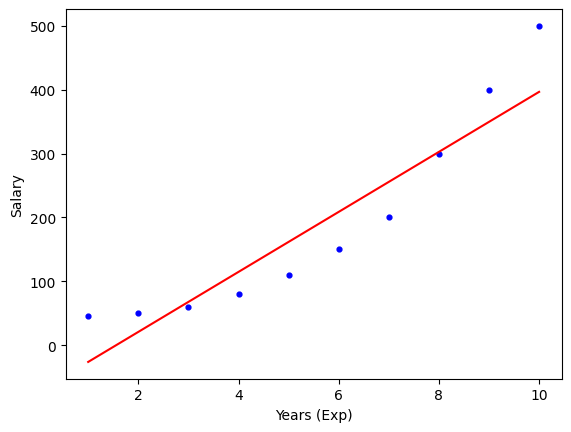
In questo esempio, viene creato un modello di regressione lineare per predire lo stipendio in base agli anni di esperienza.
Esempio 2
Ecco un esempio di utilizzo di un modello di Machine Learning con Python:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, r2_score
def predict_sales(time):
raw_data = {"years": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], "sales": [
10, 30, 50, 60, 50, 54, 67, 68, 80, 100]}
df = pd.DataFrame(raw_data)
X = np.array(df["years"]).tolist()
y = np.array(df["sales"]).tolist()
model = np.poly1d(np.polyfit(X, y, deg=3))
y_prediction = model(time)
y_prediction_test = model(X)
print("Prediction: ", y_prediction)
print("MAE", mean_absolute_error(y, y_prediction_test))
print("r2", r2_score(y, y_prediction_test))
curvy_line = np.linspace(1, 10, 100)
plt.scatter(X, y, color="blue")
plt.plot(curvy_line, model(curvy_line), color="red")
plt.show()
time = 15.5
print("Time:", time)
predict_sales(time)
# Output:
# Time: 15.5
# Prediction: 484.2656031468515
# MAE 3.1176689976690044
# r2 0.9715107549847242
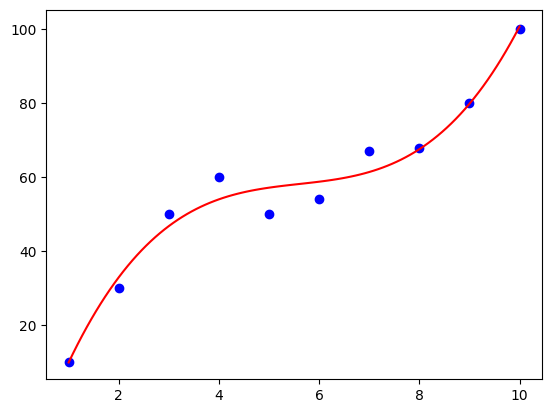
In questo esempio, viene utilizzato un modello di regressione polinomiale per predire le vendite in base al tempo.
Esempio 3
Ecco un esempio di creazione di un modello di Machine Learning con Python:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
def fitness_analyser(height, weight):
print("Height:", height)
print("Weight:", weight)
overweight_people = [[100, 90], [120, 100],
[200, 175], [80, 100], [40, 60]]
fit_people = [[60, 175], [90, 190], [80, 180], [50, 140], [30, 120]]
people = fit_people + overweight_people
is_fit = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
X = np.array(people)
y = np.array(is_fit)
train_X, test_X, train_y, test_y = train_test_split(
X, y, random_state=0, test_size=.2)
model = KNeighborsClassifier(n_neighbors=3)
model.fit(train_X, train_y)
print("Score:", model.score(test_X, test_y))
prediction = model.predict([[height, weight]])
print(f"Prediction: {prediction[0]}")
result = 'Fit' if int(prediction[0]) == 1 else 'Fat'
print(f"Prediction: {result}")
ow_scatter = [np.array(overweight_people)[:, 0],
np.array(overweight_people)[:, 1]]
f_scatter = [np.array(fit_people)[:, 0], np.array(fit_people)[:, 1]]
plt.scatter(ow_scatter[0], ow_scatter[1], color="red")
plt.scatter(f_scatter[0], f_scatter[1], color="green")
plt.scatter(weight, height, color="blue", s=100)
plt.xlabel("Height")
plt.ylabel("Weight")
plt.show()
height = 110
weight = 35
fitness_analyser(height, weight)
# Output:
# Height: 110
# Weight: 35
# Score: 1.0
# Prediction: 1 Fit
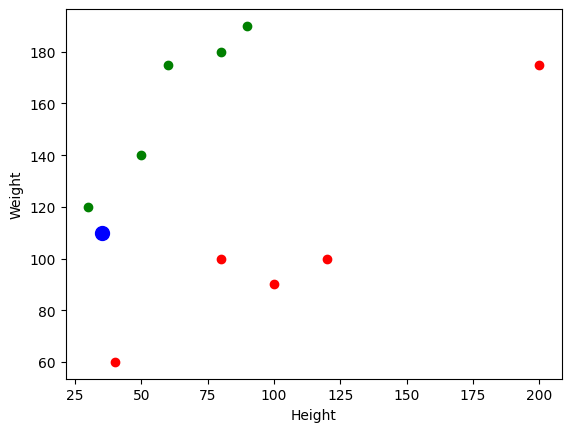
In questo esempio, viene creato un modello di classificazione K-Nearest Neighbors per predire se una persona è in forma o sovrappeso in base all’altezza e al peso.
Conclusioni
Il Machine Learning è una tecnologia molto potente che può essere utilizzata per creare modelli predittivi in diversi ambiti. Python offre molte librerie e strumenti per creare e utilizzare modelli di Machine Learning in modo semplice ed efficace.